
From improving air and water quality to protecting individual internet users from harm—accessing free flowing data can both help and hurt society. Whilst accessible data can generate benefits through innovative data driven products, services and data science initiatives, it must be used and shared in both an ethical and responsible way. Two initiatives in the regulatory and legislative field underline this view.
The European Data Act, published in February 2022, aims to make more data accessible and regulate across industries within the EU who can view and use which data and for what purposes. The British government has formulated a National Data Strategy: “There is increasing evidence suggesting that the full value of data is not being realised in the economy, and that government intervention is necessary to address specific market failures in this area”.
What could we collectively achieve if we can responsibly remove the barriers that restrict data flows?
Organizations should seize the opportunity and become responsible data stewards.
They must understand the strategic and technical measures that ensure that all parties involved have full control over the respective data when it is exchanged or processed.
“The full value of data is not being realised in the economy.”
"Here is an overview of five areas in the privacy enhancing technology and data sharing landscape where BCG Platinion can enable secure, trustworthy collaboration.
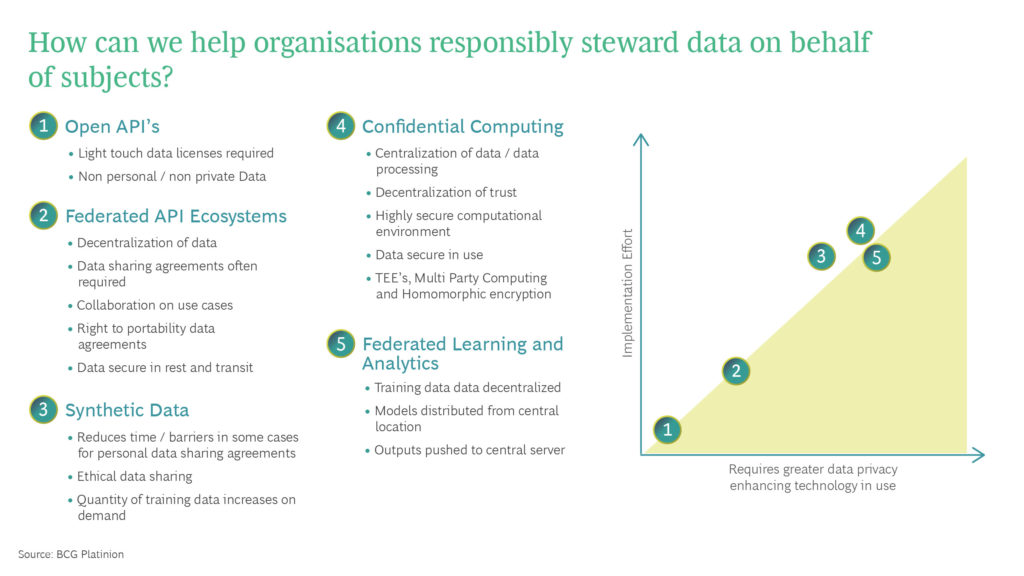
1. Open Data
Anybody can access open data. The data owner can issue licenses for it’s use (e.g. Creative Commons 1.0), but as a rule the data will not contain sensitive personal information or intellectual property. There are ways to de-identify individuals from datasets, but these techniques are not without risk, and are usually acting in the public good or in very low risk scenarios.
An example of the removal of personal data to facilitate public good is the UK governments COVID-19 dashboard, which showed cases by postcode without identifying the individuals with the illness. Open data, usually accessed via open APIs plays a key role for innovation, especially in the public sector, but is limited when sharing sensitive or personal data.
There is a way to limit API access to a set of partners, this means that more sensitive data can be shared.
2. Federated API Ecosystems
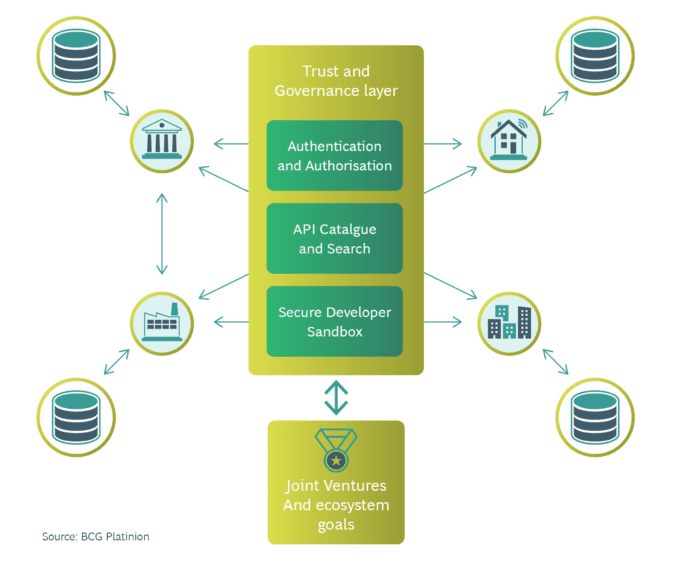
A proven approach to sharing more sensitive data is federated API access between an ecosystem of partners. These systems govern data access, including semantics, common standards, and interoperability.
They include an identity layer to authenticate all participants and define at a governance level who may access which data and for what purpose, with a set of developer friendly libraries for collaborating members to install on their infrastructure and an API catalogue for discoverability.
The advantage: Organizations retain ownership, and data is as open as it can be whilst reducing the risk of harm.
This facilitates the programmatic enforcement of data sharing and licensing agreements within a consortium of partners. Sharing “Smart data” is a key use case.
The UK national data strategy defines this as “the secure sharing of customer data with authorized third party providers, upon the customers request”.
A good example is UK’s Open Banking, which via API’s, can enable entirely new ecosystems, dynamic and changing partnerships, and shared products and services.
It can be delivered using 0auth2, the most widely used standard to meet the demands of a federated ecosystem. When combined with an identity layer called OpenID connect, a scalable security profile called FAPI (Financial Grade API).
FAPI was developed between multiple participants including the Open Banking Implementation Entity (OBIE) in the UK, ISO TC68, the Australian Consumer Data Standards Body, Financial Data Exchange (FDX) alongside others. Hence, the majority of markets that move in to Open Data have chosen FAPI standards, because it is proven, secure, cost saving due to it’s wide range of vendor support and adaptable. There is also a path globally interoperability if a common security profile is used.
It can be very time-consuming to reach agreements on data sharing, especially when personal or commercially sensitive data is involved. 18 months or longer is not uncommon. Ultimately, many promising collaborations fail because of this before they have even really begun. But there are ways to share the value of personal data without revealing the raw content itself.
3. Synthetic data
Personal or sensitive data is subject to numerous legal restrictions to ensure that it remains private. Using synthetic data techniques, data sets are artificially generated to contain the same statistical properties as the original, but do not contain sensitive information.
The topic is still new, but has the potential to replace most of the data used in machine learning in the future. When used in the context of federated API ecosystems or Open API’s, synthetic data can unlock the possibility to share much more detailed datasets. This can be incredibly powerful when creating an open call to solve a problem, like medical research or smart city design, without exposing any legally sensitive information.
A spectrum ranging from simplistic schema replication all the way to replicating almost all the detailed statistical patterns exists. Detailed patterns can be produced by Bayesian networks, but if this is too computationally expensive or there is insufficient data to generate a new data set, a histogram can be derived for each attribute, with noise added to achieve differential privacy.
These techniques ensure secure data exchange at rest and in transfer, but what if an organization wants to protect data in use as well? What if we could run machine learning experiments on private data, without ever seeing the original data set? Emerging Privacy Enhancing Technologies (PETs) lend themselves to this, which is particularly important in terms of consumer protection and regulatory compliance.
4. Confidential Computing
One of the biggest problems in data exchange is copying and bundling data, i.e. processing. How can we prevent data being copied in a computer system that is explicitly designed for this purpose? How can we prevent data being inadvertently shared whilst allowing it to be shared? An exciting application of this is to allow data scientists to run experiments on encrypted data. This means they will be able to produce results without being able to read or understand the data they are analyzing.
There are three approaches to retaining data protection during processing, they are broadly defined as Privacy Enhancing Technologies (PET’S):
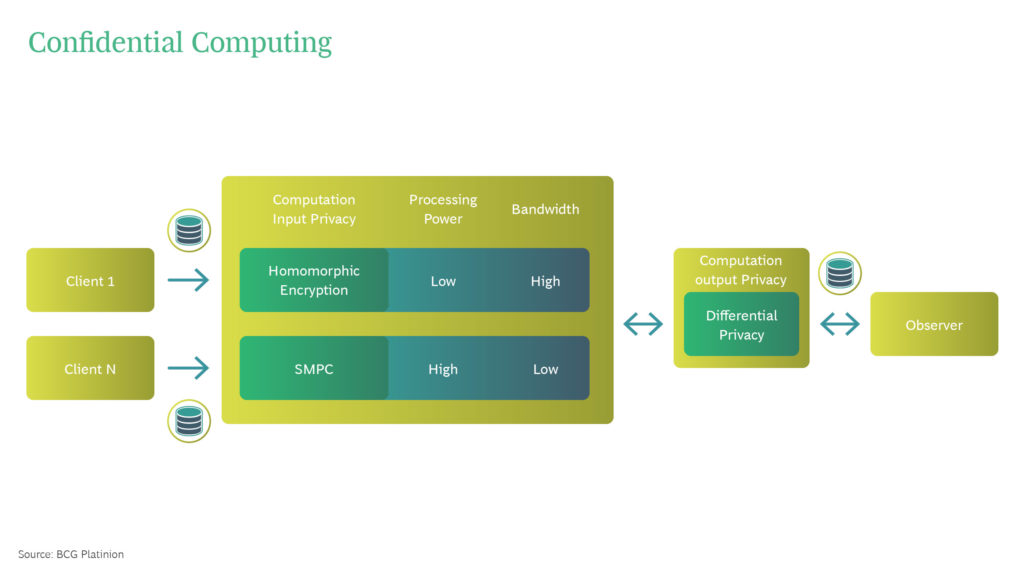
Input privacy
In order to guarantee a shared computation retains input privacy, multiple participants must be able to participate in a computation without the other knowing what data each participant has shared. The following encryption technologies are designed for this purpose:
- Homomorphic Encryption (HE) allows computations to be performed on encrypted data. This means that sensitive information is never revealed to the party performing the calculation. Only certain calculations are permitted, hence the data owner retains complete control of a data set. However, computations can be very costly to perform, hence if data is very large, encrypting these large data sets can be very computationally expensive. In addition, most homomorphic encryption schemes have security vulnerabilities that do not exist with classical encryption. The field is evolving however, and in many cases HE is an incredibly powerful tool for privacy protecting data science.
- Secure Multi Party Computation (SMPC) involves algorithms where multiple people compute the output while their respective input remains hidden from each other. This allows business partners to exchange data, perform calculations and arrive at a joint result in compliance with some predefined rules.
What technology should be used and when? SMPC places a load on the network because many gigabytes of metadata are used for calculation. HE, on the other hand, places few demands on the Internet connection, but larger amounts of computing power is required.
This is because there are additional computing steps involved. So, if you have very fast computers but slow Internet, HE is suitable. SMPC is the better choice if, as in the case of IoT, the computers have low performance, but fast Internet is available.
Output privacy
Input privacy does not directly lead to output privacy, even if we can assume there is a reasonable chance it does. What if a partner responsible for the output data tricked only one input data provider to submit their data in a calculation?
They would know what the input data contains. Differential privacy prevents conclusions from being drawn about the input through the output:
Differential Privacy masks data with noise. The original information is thereby deliberately obfuscated. For example, statistics about a large group of people can be aggregated. Applied to synthetic or encrypted data, this is a powerful way of protecting anonymity whilst protecting the integrity of a dataset.
Hardware Based Approaches
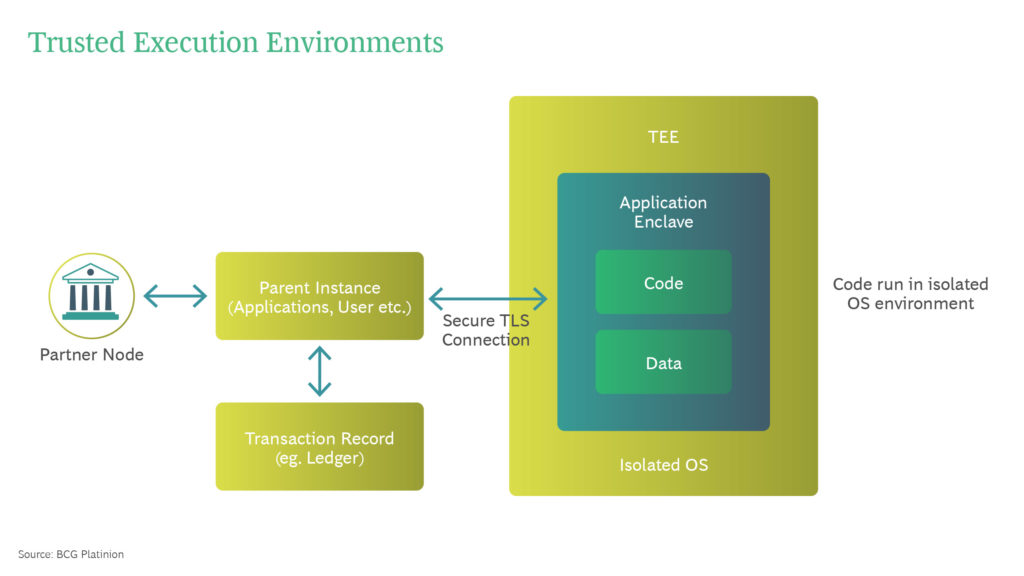
Another worthy addition to the Privacy Enhancing Technology landscape is Trusted Execution Environments.
Trusted Execution Environment (TEE) are isolated virtual machines. They have no memory, do not allow interactive access and have no external network access.
A secured communication channel, for example via Transport Layer Security (TLS), ensures that data enters the TEE securely. SDKs such as Open Enclave can be used to deploy and build Enclave applications.
They consist of an untrusted component (the host) and a trusted component (the enclave). The enclave refers to a protected memory area that ensures the confidentiality of data and code execution and is usually protected by the hardware.
5. Federated Learning
This high-performance technique runs computations on distributed data sets. And it does so wherever the data resides—for example, on the IoT, on mobile devices (cross-device), or on different enterprise servers (cross-silo).
This is an incredibly powerful technique for training machine learning models on private data. Hyperparameters are shared among all participants to improve the model.
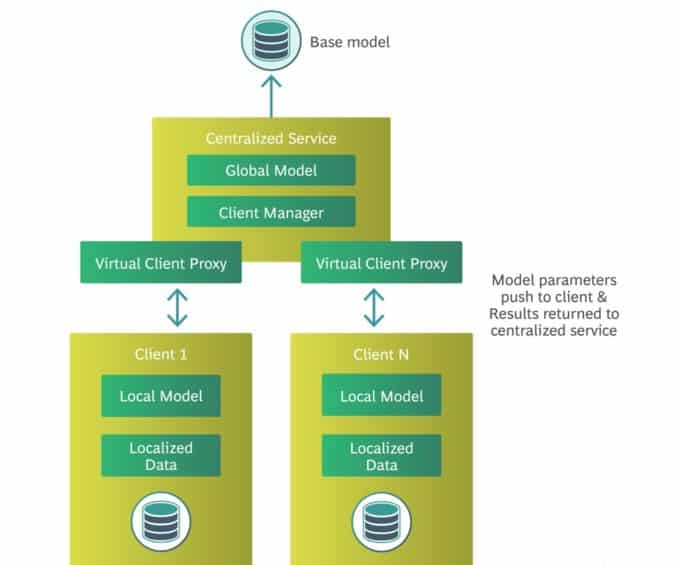
Within the system, data is never transferred from its source. Organizations can thus collaborate without jeopardizing data protection.
Typical model frameworks for federated learning are TensorFlow and PyTorch.
In order to network participants and send messages, new networking frameworks such as TensorFlow Federated and Flower can be used.
A central service manages the participants in the network.
The key purpose of this service is for authentication and to administer training sessions.
Client design is important here. It is necessary to have the model parameters synchronized by a central service and to perform client-side model training operations. It is also necessary to clarify how authentication between the client and the server works, how the client system is deployed and versioned, and how the process is monitored.
To do this, the federated learning system needs to know what private data should be used by each client to train the local models. This is complicated as data may also be aggregated with data generated by the client or central service environments, and this needs to have input and output privacy characteristics.
Confidential computing techniques can help here. However, it remains important to honestly assess the data protection risks of the system.
Conclusion
Removing barriers to data sharing can foster important new developments within digital solutions, particularly within the field of artificial intelligence.
Whilst society can benefit from this in many ways, organizations should act responsibly and protect their data appropriately.
We have shown you how this can be done by looking at five areas of private AI and data exchange.

About the Authors
Tom is an Engineering Lead based in the London office. He has vast experience delivering products and services with a human centered approach – including artificial intelligence solutions at scale and new startup ventures across a wide range of industries. Covering topics ranging from privacy enhancing AI to digital consortium design, he brings expertise in open innovation’s evolving role in solving high impact issues such as climate action, healthcare and online privacy.
Jamie is an Engineering Director from London with extensive experience managing software development teams in both startup and enterprise companies. With industry experience across consumer, energy and insurance sectors he brings a human centered approach to product delivery, innovation and platform design with a passion for sustainable engineering practices and AI assisted solutions.
A Managing Director based in the London office, Phil is a key member of BCG Platinion’s DPS and design team leadership in EMESA. He has extensive experience in innovation, having spent almost 20 years running his own product design and innovation practice which BCG acquired in 2019, which saw him work for many of the world’s leading tech companies including Google, Apple and Microsoft, alongside a wide array of start-up ventures.
