
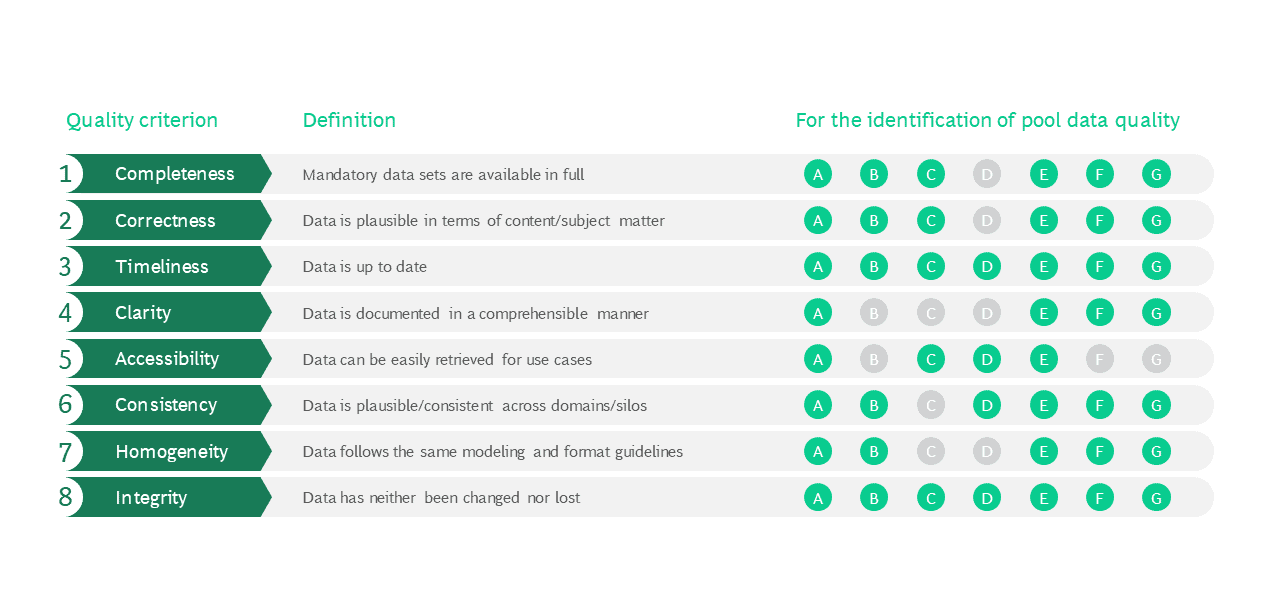
The best AI model cannot provide a correct result if the data used is flawed. Data quality is one of the most important success criteria for AI projects. But when is the available data deficient? We show eight quality criteria that can be used to make an assessment.
Testing methods to detect poor data quality
A deficiency is assumed if at least one of the following questions is answered with „No“ for a data set or data group:
Whether a criterion is met or not can be checked using various approaches. Independent of the application the following test methods are suitable:

A. Quality check by domain experts: These check the inventory data on a random basis (feasible checking tools: Alterys, Trifacta and Jupyter).
B. Automated quality testing: With a regular flow of input data, automated tools perform ongoing plausibility, completeness and consistency checks (feasible checking tools: Informatica, Talend and pytest).
C. Data monitoring: This method monitors source systems with regard to various key figures. These include, for example, completion times for data transformations, data changes, IT availability indicators from or technical error messages from the systems (feasible checking tools: Grafana, Kibana and Splunk).

D. Error ticket analysis: Error tickets can contain anomalies – for example, multiple complaints about unavailable data – from which data quality deficiencies can be deduced. They are created, for example, by the service desk in the context of data-relevant systems (feasible checking tools: Jira and ServiceNow).
E. Data management analysis: It examines technical/specialist data documentation – such as the metadata documentation and wiki entries for data points – and checks for missing responsibilities and data domains with inadequate quality assurance processes (feasible checking tools: Atlassian Confluence and IBM Watson Knowledge Catalogue).

During the development of a specific use case these test methods are useful:
F. Initial data evaluation: The prerequisite is data extraction from the source system. This is followed by a detailed, use case-related, technical and functional data check. The implementation of the data-related use case always remains in view, including the suitability check of the data format and normalization as well as the check of historical developments of the data basis (feasible check tools: Alteryx, Trifacta and Jupyter).
G. Continuous testing: For this purpose, small-step automated, use case-related, functional and data-specific tests are used, which are integrated into the automated processes for going live (feasible testing tools: pyunit, Jenkins and GitLab).
Approaches for improving data quality
Approaches to data deficiencies can be reactive – fixing existing errors – or proactive – preventing the occurrence of errors. BCG Platinion’s approach to capturing and addressing poor data quality is both reactive and proactive, with two reactive and one proactive approach adopted. The reactive solution approaches presented here assume that data deficiencies have already been identified by the testing methods mentioned above.
Reactive Solution Approach 1: Correct incorrect data
Inconsistent and inaccurate data is caused, for example, by end-user mis-entry, sensor mis-measurement, outdated or incorrectly linked data. Depending on the individual case, one or more of the following methods may be suitable for improving data quality. The extent to which the corrections here are made manually or (partially) automatically depends strongly on the amount of data:
- Source data cleanup: The erroneous data source or link must be identified. Afterwards, the error can be fixed locally – for example, by correcting the data extraction/integration algorithms or using a more suitable source.
- Manual/semi-machine correction: This requires the involvement of subject matter experts. If the amount of data is small, manual correction may be sufficient; otherwise, a definition of error selection and correction algorithms using data wrangling tools such as Trifacta is necessary.
- Correction services: Internal and external services can be used for automatic correction. One example is georeferencing services to improve postal code information.
- Elimination: By means of defined filter criteria, implausible rogue results can be deleted, provided that sufficient residual data records remain

Reactive Solution Approach 2: Fill data gaps
If data is incomplete, research should be conducted to determine the causes. Often such problems are the result of losses during previous system migrations. For these cases there are four different correction methods, which – depending on the missing data point – can be combined with each other:
- Deduction: Missing numerical or categorical values are derived from the existing data in a rule-based manner. The simplest example is the addition of the city name based on the postal code.
- Augmentation: If the amount of data is simply too small, as in the case of an image with too low a resolution, new, plausible data points can be generated from existing data – a method suitable for training neural networks, for example.
- Interpolation: In the simplest case, missing numerical values such as temperature curves can be calculated from the previous and subsequent values by averaging. If a whole data series is missing, more complex regression algorithms can be used for its emulation.
- Imputation: Deep learning algorithms can help to determine missing categorical values – for example in the case of empty fields in a table.
Correction methods based on regression or deep learning, like the latter two, increase the complexity of AI development. They should therefore only be used when simpler procedures such as data exclusion (elimination) or changing the data source (source data cleansing) are insufficient.

Proactive Solution Approach 3: Data management and governance
Naturally, it is best to identify and avoid impending data deficiencies right from the start. This requires the establishment of stringent data management and governance to ensure high quality throughout the entire data lifecycle.

- Monitoring: Dashboards can be used to monitor key quality metrics such as timely data transformation.
- Data governance/quality gates: Both technical and functional quality managers should be appointed to check newly created data; their roles should be anchored accordingly in the development processes.
- Data quality guidelines: Binding guidelines should be defined and regularly reviewed for modeling, storing, documenting, and processing data.
- Data communities: In order to exchange ideas about data-based use cases and their optimization potential, it is helpful to build up corresponding communities.
- Digitalization: In general, the strategic alignment of digital use cases makes sense. This is possible through more intensive digitalization of analog data, more technical interfaces and the formation of digital self-service offerings. Digital applications, for example, can replace paper forms.
This proactive approach must take into account that increased data management can delay the development of solutions. Such measures should be streamlined and also only used where data quality deficiencies accumulate.

Conclusion
AI models can only work effectively with good data. Ensuring high data quality is not a one-time step, but a continuous process. Thus, data-driven companies should use these testing mechanisms not only during the initial AI development, but also regularly during ongoing application.
Find out more about AI here:
- |
What You Always Wanted to Know About AI and More
Learn MoreA guide to how AI can really benefit your business

- |
AI: Choosing the right approach to machine learning for your needs
Learn MoreThis first article in our AI series gives an overview of the three common machine learning methods and their application areas.

- |
Model Accuracy in AI: How Accurate is Accurate Enough?
Learn MoreThe second article of our AI series dives deep into quality and performance of models used.

- |
AI: Detect and Avoid Bias at an Early Stage
Learn MoreIn article three of our AI series we present a method to succeed in minimizing bias to get realistic results from AI models.

- |
AI: Success Factor Data Preparation
Learn MoreArticle five of our AI-series highlights the right selection of data.

About the Authors
Jakob Gliwa
Associate DirectorBerlin, Germany
Jakob is an experienced IT, Artificial Intelligence and insurance expert. He led several data-driven transformations focusses on IT-modernization, organization and processes automation. Jakob leads BCG Platinion’s Smart Automation chapter and is a member of the insure practice leadership group.
Dr. Kevin Ortbach
BCG Project LeaderCologne, Germany
Kevin is an expert in large-scale digital transformations. He has a strong track record in successfully managing complex IT programs – including next-generation IT strategy & architecture definitions, global ERP transformations, IT carve-outs and PMIs, as well as AI at scale initiatives. During his time with BCG Platinion, he was an integral part of the Consumer Goods leadership group and lead the Advanced Analytics working group within the Architecture Chapter.
Björn Burchert
Principal IT ArchitectHamburg, Germany
Björn is an expert for data analytics and modern IT architecture. With a background as data scientist he supports clients across industries to build data platforms and start their ML journey.
Oliver Schwager
Managing DirectorMunich, Germany
Oliver is a Managing Director at BCG Platinion. He supports clients all around the globe when senior advice on ramping up and managing complex digital transformation initiatives is the key to success. With his extensive experience, he supports clients in their critical IT initiatives, ranging from designing and migrating to next-generation architectures up to transforming IT organizations to be ready for managing IT programs at scale in agile ways of working. He is part of the Industrial Goods leadership group with a passion for automotive & aviation.
