
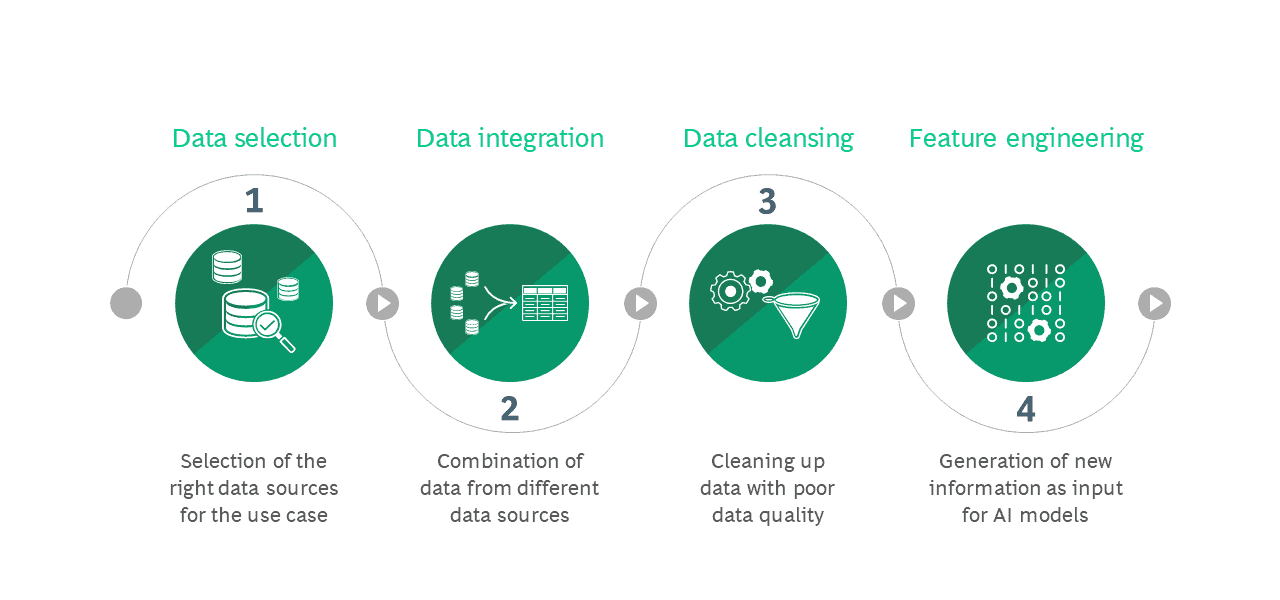
Data is the raw material of any AI application. In most companies, it is available in abundance. However, data only reveals its added value when it has been properly prepared for analysis. A successful AI project therefore requires not only an error-free algorithm, but also a suitable database. Data preparation and data cleansing accordingly account for nearly 80 percent of the work put into an AI application. We have developed a framework specifically for this purpose based on the standard process model for data analysis, the so-called Cross Industry Standard Process for Data Mining (CRISP-DM). The procedure essentially consists of four steps that build on each other: First of all, Data Selection takes place to pick the data, Data Integration is the step during which data from different sources is merged and combined, unusable data is cleansed or removed in Data Cleansing, and finally new information is created in a process called Feature Engineering.

Data Selection
For a planned AI application, the first step is to identify the appropriate data sets, data sources, and data attributes. Which data provides the desired statements for the project and where is it available? Which data attributes are necessary, and which are not?
“The best possible source for the use case can be selected based on data quality, technical access capabilities, and speeds.”
" Jakob Gliwa, PrincipalA typical AI application is the optimization of traffic flow at peak times, coupled with situation-dependent traffic-light control. First of all, road and traffic-light circuit plans are important for this, and traffic monitoring data and external weather data are also used.
Multiple sources are often available, so the best possible source for the use case can be selected based on data quality, technical access capabilities, and speeds. The size of the data sets is particularly important.
If too little data is available or if the data sets are incomplete, the result is a bias and, in the end, an incomplete representation of reality. It is also important to continuously monitor data sources in case they provide regular automated input. This is because if changes are made to the data model, errors can accumulate in the subsequent preparation steps, which then negatively affect the AI model.
The selection of attributes within the data set requires special attention. At the beginning of an AI project, you may well select more attributes than you need. Over the course of time, experiments crystallize the attributes that are actually relevant. Those that are not needed can and should then be discarded. This streamlines the amount of data and increases the processing speed.
Data Integration
The data relevant to an AI project often stems from different sources that need to be merged. This is a complex process, as the data schemas have to be mapped onto each other and the semantic differences clarified.
For example, personal data often comes from different data sources, which makes it difficult to assign data sets unambiguously. There are many reasons for this, such as unrecorded address changes, the abbreviations used, or different spellings of names.
The path to uniform data sets leads through three steps: Schema Alignment brings together data with different schemas, for example if the name is contained in different columns or the same columns have different names. The data schemas can be automatically or manually converted into a standardized schema for the AI application to work with.
In a further step, Record Linkage, entries are searched for that refer to the same facts. Comparisons, AI applications, or fuzzy matching – identifying data that is similar but not a complete match – can detect and remove duplicates. In the third step, Data Fusion, what belongs together comes together. The identified entries now form a unit, an entity. However, the different information of the respective entries is always preserved.

Data Cleansing
Then it is necessary to clean the integrated data. Essentially, this means removing duplicates, checking manually-entered form data for completeness, and correcting possible errors. If data is missing, it can be added using a previously developed set of rules – for example, predefined default values. Important: The data formats should be harmonized so that they describe the same facts. For example, a date can be specified in many different formats, but for use in an AI model it must be consistent. The last thing to do is to look for rogue data. With the help of statistics and data profiling, it is possible to identify highly abnormal values in the normal data. These are either deleted or, if necessary, corrected using a set of rules. Finally, the cleaned data must be stored in such a way that it can be used as easily as possible.
Feature Engineering
In order for the data to be suitable for its intended purpose, it must be transformed in a final phase called Feature Engineering. This includes the transformation, construction, reduction and formatting of the data. The focus is on individual variables. For example, a person’s age information can automatically generate a Yes/No field indicating whether the person is of legal age.
- With Data Transformation, the date type or distribution changes. Different methods are used depending on the data type. When a model can only handle numeric data, one-hot encoding is often used, with a category-type variable reformatted into multiple binary variables. In addition, it is useful to normalize numerical values over a normal distribution during data transformation, as this can significantly improve the performance of many models.
- With Data Construction additional variables are generated from already existing ones, such as the mean value of all the purchase totals of a person.


-
Data Reduction compresses data to a smaller size with the goal of increasing processing speed or anonymization. This removes the unambiguous assignment of the data to a person. The result-relevant features of the original data are of course preserved.
-
Data Formatting converts the data into a form that the target model can work with. The dimension, the target model and possibly also the libraries used play a role here. If the data has a high dimension, hierarchical data formats such as HDF5 can be used.
Conclusion
One of the most important prerequisites for the success of AI projects is the accurate preparation of the data to be used. The framework developed and tested by BCG Platinion makes it possible to select, merge, cleanse and optimally prepare the necessary data for the respective project in a standardized process.
- |
What You Always Wanted to Know About AI and More
Learn MoreA guide to how AI can really benefit your business

- |
AI: Choosing the right approach to machine learning for your needs
Learn MoreThis first article in our AI series gives an overview of the three common machine learning methods and their application areas.

- |
Model Accuracy in AI: How Accurate is Accurate Enough?
Learn MoreThe second article of our AI series dives deep into quality and performance of models used.

- |
AI: Detect and Avoid Bias at an Early Stage
Learn MoreIn article three of our AI series we present a method to succeed in minimizing bias to get realistic results from AI models.

- |
AI: Data Quality: What to do When Errors Occur?
Learn MoreArticle four of our AI-series puts a lense on the importance of the quality of data used.

About the Authors
Jakob Gliwa
Associate DirectorBerlin, Germany
Jakob is an experienced IT, Artificial Intelligence and insurance expert. He led several data-driven transformations focusses on IT-modernization, organization and processes automation. Jakob leads BCG Platinion’s Smart Automation chapter and is a member of the insure practice leadership group.
Dr. Kevin Ortbach
BCG Project LeaderCologne, Germany
Kevin is an expert in large-scale digital transformations. He has a strong track record in successfully managing complex IT programs – including next-generation IT strategy & architecture definitions, global ERP transformations, IT carve-outs and PMIs, as well as AI at scale initiatives. During his time with BCG Platinion, he was an integral part of the Consumer Goods leadership group and lead the Advanced Analytics working group within the Architecture Chapter.
Björn Burchert
Principal IT ArchitectHamburg, Germany
Björn is an expert for data analytics and modern IT architecture. With a background as data scientist he supports clients across industries to build data platforms and start their ML journey.
